"Ez nem emberi lépés. Még sosem láttam embert megtenni egy ilyen lépést. Ez gyönyörű."[2]
A Föld országainak adatvédelmi hatóságait és adatvédelemmel, magánszféra védelemmel foglalkozó biztosait, szervezeteit tömörítő, évente megrendezésre kerülő nemzetközi konferencia, az "International Conference of Data Protection and Privacy Commissioners" 2018-as őszi ülésén elfogadott egy nyilatkozatot, amely a mesterséges intelligencia és a személyes adatok védelmének néhány kapcsolódó kérdését vizsgálja.[3] A Nemzeti Adatvédelmi és Információszabadság Hatóság (röviden: NAIH) munkatársaként lehetőségem nyílt arra, hogy részt vegyek a nyilatkozat megszövegezésében.
A mesterséges intelligencia és a jogi szabályozás egyes kérdéseit vizsgáló korábbi publikációim, a nyilatkozat megszövegezésében való közreműködés, továbbá a területen az elmúlt időszakban elkezdődő aktív szakmai és tudományos diskurzus sarkalt arra, hogy a jelen publikációban kíséreljem meg - a teljesség igénye nélkül - bemutatni a mesterséges intelligencia, ezen belül a gépi tanulás és a személyes adatok védelmének egyes kérdéseit. Ez azért is rendkívül aktuális, mivel az Európai Unió 2018-ban alkalmazandóvá vált új általános adatvédelmi rendelete (679/2016 EU rendelet, közkeletű angol rövidítéssel: GDPR) külön rendelkezéseket szentel a kizárólag automatizált úton létrejövő, személyes adatokat érintő döntéshozatalnak. A GDPR vált így az első jelentősebb jogi eszközzé, amely kifejezetten foglalkozik a kizárólag gépi úton létrejövő, algoritmikus alapú döntések joghatásainak szabályozásával. Az MI által hozott döntések ma már a mindennapok részévé váltak és az európai jogalkotó is felismerte annak társadalmi jelentőségét és a szabályozás igényét. Az MI működésének adatvédelmi vizsgálata szempontjából talán az egyik legfontosabb terület az ún. "gépi tanulás" jelensége, amely során a szoftver a belé töltött adatok alapján "tanul" és hoz meg különböző döntéseket. A gép által hozott döntés pedig akár egy adott személyre is kihatással lehet.
Jelen tanulmány az MI társadalmi hatásának általános bevezetésével indít. Ezek után felvázolom a gépi tanulás és ezzel összefüggő adatkezelés egyes adatvédelmi jogi szempontból releváns kérdéseit. Később bemutatok a mesterséges intelligencia és személyes adatok védelmének kapcsolatáról eddig született néhány nemzetközi dokumentumot és röviden kitérek a fő kijelentéseinek vizsgálatára. A tanulmány második felében bemutatom a GDPR
- 669/670 -
vonatkozó előírásait, és azok alkalmazhatóságával kapcsolatos egyes kérdéseket és válaszokat.
A tanulmány célja rávilágítani arra, hogy a közeljövőben minden bizonnyal egyre több, akár a személyünket is érintő döntést fognak meghozni emberi beavatkozás nélkül különböző szoftverek. A döntések meghozatalához pedig ezek a szoftverek a legtöbb esetben nem mást használnak fel, mint a mi személyes adatainkat. Szeretném ezért felhívni a szakma figyelmét az MI és a gépi tanulás társadalmi hatásaira és az azzal kapcsolatos adatvédelmi szabályozási problémákra, hiszen ismerve a technológia fejlődési irányait, a terület jogi szempontú vizsgálata, elemzése és értékelése is minden bizonnyal egyre nagyobb jelentőségre fog szert tenni a jövőben.
A mesterséges intelligenciával kapcsolatban egységes fogalomról nem beszélhetünk, bár annak definiálására több kísérletet találunk a vonatkozó szakirodalomban. Az Oxford számítástechnikai értelmező szótár szerint az MI a számítástudománynak az a területe, amely emberi intelligenciát igénylő feladatokat megoldó számítógépes programok készítésével foglalkozik.[4] Az Európa Tanács honlapjának MI-vel foglalkozó aloldalán található tudástár szerint pedig mesterséges intelligenciának olyan tudományos eredmények, teóriák és technikák tekinthetőek, melyek végső célja gépek képessé tétele az ember kognitív képességeinek reprodukálására. A jelenlegi fejlesztések célja több területen, hogy a korábban ember által végrehajtott, összetett gondolkodást igénylő feladatokat gépekkel végeztessenek el.[5] John McCarthy véleménye szerint - amely elsősorban mérnöki szempontból közelíti meg a problémát - az MI az intelligens gépek gyártásának tudománya és mérnöki gyakorlata.[6] Közös pontként ezért elsősorban a gépek, műszerek és ezeket működtető programok, szoftverek intelligenciával való felruházását emelhetjük ki.
A következő táblázat azt szemlélteti, hogy mik a különbségek és hasonlóságok egy egyszerű program és az MI között.[7]
| "Egyszerű" program | Mesterséges intelligencia |
| - Programozó írta. - Determinisztikus: ugyan arra a kérdésre ugyanazt a választ adja. - Igen-nem, 0-1 jellegű eredményt ad. - A programozó mondja meg (előzetesen), hogy mi a helyes eredmény. - Szabályokat futtat, nincs helye a szabályok felülírásának. | - Programozó írta. - Valószínűséggel dolgozik: bizonyos eséllyel ugyanaz a válasz az adott kérdésre. - Kevésbé-jobban: pl. 85%-15% jellegű eredményt ad. - A programozó csak a célt adja meg, az MI kísérletezi ki a helyes eredményeket. - Mintákat vizsgál. - Helye van a meglepetéseknek és a hangsúlyok eltolásának. |
Filozófiatörténeti szempontból Stuart Russel és Peter Norvig az MI fogalmának filozófiai fejlődése szempontjából négy féle irányzatot különböztet meg, amelyek a következők:
(1) Emberi módon gondolkodó rendszer: Az emberi elme működését és a megismerést modellező rendszereket tekinti ez az irányzat MI-nek.
(2) Emberi módon cselekvő rendszer: Ez a megközelítés Alan Matheson Turing matematikus nevéhez kötődik, aki a róla elnevezett Turing-teszt alapján az emberi viselkedést állította az intelligencia fő kritériumának, és az elérendő célnak.
(3) Racionálisan gondolkodó rendszer: Ez az irányzat az emberi gondolkodásnál valamilyen értelemben tökéletesebb, racionálisabb gépek és szoftverek megalkotásában látja az MI fejlesztés célját.
(4) Racionálisan cselekvő rendszer: A modern informatikai tudományok megközelítése, amely nem tűzi ki azt célul, hogy a kialakított rendszerek a szó klasszikus értelmében gondolkodjanak, vagy imitálják az emberi viselkedést, csak azt, hogy minél racionálisabban viselkedjenek (pl. egyértelműen tudják diagnosztizálni a betegségeket, jelezzék előre a természeti katasztrófákat).[8]
John R. Searle szerint továbbá különbséget tehetünk gyenge és erős MI között. Gyenge MI-nek Searle azon rendszereket tekinti, amelyek úgy cselekszenek, mintha intelligensek lennének, de ennek ellenére arról már nincs információ, hogy a rendszer valóban rendelkezik-e elmével, vagy sem. Az erős MI ezzel szemben az olyan rendszerekre értendő, amelyek valóban gondolkodnak, önálló tudatuk van.[9]
A "teremtett értelem" társadalomra gyakorolt hatásának problémája ősidők óta foglalkoztatja az embereket. Az egyes történetek mögött általában az a mélyen gyökerező ősfélelem lapul meg, hogy az önálló tudatra ébredő mesterséges lény akár el is pusztíthatja a megteremtőjét. Ezen pesszimista irányzatok gyökerei a XX. század előt-
- 670/671 -
ti szépirodalomban és folklórban is megtalálhatóak (pl. Frankenstein története).
Az emberek és a mesterséges lények közötti konfliktus nem csak az irodalmi fikció szintjén jelent meg. Az ipari forradalom alatt a gépektől való rettegés szülte például a géprombolók mozgalmát az 1810-es években.[10] A pesszimista elméletek alapját - amelyek szerint a teremtett lény fellázad és eltörli teremtőjét a színtérről -, elsősorban az úgynevezett "technológia szingularitás" problémája adja. Ray Kurzweil szerint a szingularitás egy jövőbeli korszak, melyben a technológiai változás üteme olyan gyors lesz, a hatása pedig olyan mély, hogy az emberi élet visszafordíthatatlanul átalakul. A szingularitás hatására megjelenő emberfeletti intelligencia miatt a technológiai fejlődés és ezzel összefüggésben a társadalmi változások oly mértékben felgyorsulnak, hogy a környezet megváltozását a szingularitás előtt élők képtelenek felfogni. A technológia szingularitás, avagy intelligenciarobbanás utáni eseményeket az elmélet szerint tehát a jelenlegi jövőképeinkkel képtelenek vagyunk megjósolni. A szingularitás nyomán megjelenő szuperintelligens mesterséges lények pedig könnyen kiszoríthatják az embert a létezésből.[11]
Más, optimistább elméletek (pl. I. J. Good, Moravec) szerint az embereket leigázó MI víziója az ismeretlentől, emberfelettitől való rettegésből fakad, csakúgy, mint korábban a szellemektől, vagy boszorkányoktól való félelem. Az optimista felfogás szerint, ha az MI-t megfelelően, azaz olyan ágensekként tervezik, amelyek a gazdáik céljait teljesítik, akkor a jelenlegi tervezés lépésenkénti előrehaladásából származó MI-k szolgálni fognak, nem pedig leigázni. Az emberek azért használják agresszíven az intelligenciájukat, mert a természetes kiválasztódás miatt velük született agresszivitással rendelkeznek. De a gépek, amiket magunk építünk, nem születnek agresszívnak, hacsak nem döntünk úgy, hogy ilyennek építjük őket. Másrészt viszont lehetséges, hogy a számítógépek meghódítanak minket abban az értelemben, hogy szolgálatukkal elengedhetetlenné válnak, csakúgy, mint ahogy az autók meghódították az iparosodott világot.[12]
A fentiek alapján is világosan látszik, hogy az MI ideális társadalmi és ezzel összefüggésben jogi szabályozása rendkívül fontos kérdés, és annak jelentősége minden bizonnyal egyre fontosabb lesz az idő előrehaladásával.
A manapság már nap, mint nap használt MI alapú rendszerek, szoftverek és eszközök olyan új típusú megoldásokat nyújtanak, amelyek nagyon sok esetben a felhasználók személyes adatainak kezelésével, feldolgozásával járnak együtt. A lakossági felhasználásra szánt otthoni robotok, vagy az emberi viselkedést elemző okostelefonos applikációk folyamatosan monitorozzák a felhasználóik viselkedését és reakciót annak érdekében, hogy minél tökéletesebb tudják kiszolgálni az igényeiket. Nem véletlen, hogy az ilyen modern technológiai megoldást használó eszközöknél és szolgáltatásoknál szinte ma már minden esetben fontos kulcsszó a személyre szabottság.
A személyre szabottság mellett azonban egyre nagyobb az igény az olyan technológiákra is, amelyek képesek előre megjósolni a felhasználó igényeit. Ez már sokkal bonyolultabb döntési mechanizmusokat feltételez, amelyeket leginkább MI alapú öntanuló rendszerekkel lehet kiváltani. A Norvég Adatvédelmi Hatóság (Datatilsynet) témába vágó jelentése úgy írja le az MI-t, mint egy olyan rendszert, amely képes a saját tapasztalatai alapján tanulni és a megszerzett tudást eltérő helyzetekben alkalmazni összetett problémák megoldására. A koncepció lényege, hogy az MI az általa "látott" (a gyakorlatban tulajdonképpen bele töltött) személyes adatokból tanul és dönt vagy "jósol".[13]
Az alábbi pontokban kísérlem meg ezért áttekinteni az MI és a személyes adatok kapcsolatának főbb kérdésköreit.
A három fenti fogalmat sokszor szinonimaként használják, azonban azok nem fedik teljes mértékben egymást. Az MI gyűjtőfogalomként szolgál, amely magában foglal valamennyi olyan eljárást, amikor egy szoftver automatikusan hoz meg egy döntést. A gépi tanulás ehhez képest szűkebb fogalom, amely az MI fejlesztés egyik ágát jelenti. Ennek lényege, hogy a rendszer tapasztalatokból generál önálló tudást. A rendszer példa-adatok, minták alapján képes önállóan, vagy emberi segítséggel szabályszerűségeket, szabályokat felismerni és meghatározni, majd az elsajátított tudásbázisban felfedezett szabályszerűségek alapján döntéseket hozni.[14]
A "deep learning", vagy magyarul mélytanulás pedig a gépi tanulás egyik ágát jelenti. A mélytanulás neuronhálózatok alkalmazásán alapszik, azokon a statisztikai modelleken, amelyeket 1943-ban Warren McCulloch és Walter Pitts alkotott meg a biológiai ideghálózatok mintájára.[15] Az algoritmus itt is a beletáplált (múltbeli) mintázatok alapján próbálja meg előre jelezni a következő lehetséges értékeket, azonban a koncepció itt nem áll meg.
- 671/672 -
A mélytanulást végző neuronhálózat több rétegű (általában már tanított) adatbázisból és rájuk épülő tanuló algoritmusokból épül fel. Ennek köszönhetően a rendszer absztrakciós készsége is növekszik a megoldásra váró feladatokkal kapcsolatban.[16]
A tanulmány hátralévő részében nem a tágabb értelemben vett MI, hanem az ebben benne foglalt gépi tanulás jelenség szempontjából elemzem elsősorban a problémákat, mivel adatvédelmi szempontból ez adja talán a legfontosabb megválaszolásra váró kérdéseket. A továbbiakban, ahol az MI fogalmát használom, ott az alatt szükségképpen a gépi tanulást értem.
A gépi tanulás során az MI-rendszer által végzett adatkezelést három lépcsőre lehet bontani, amelyek a következők:
(1) Először a rendszerbe betáplálnak nagy mennyiségű adatot, ebben az adathalmazban pedig az algoritmus megpróbál mintákat, hasonlóságokat keresni. Amennyiben az algoritmus talál ilyen azonosítható mintákat, úgy azokat megjegyzi és elmenti későbbi használat céljából. A megjegyzett és elmentett minták alapján ezek után a rendszer egy modellt generál. A rendszer a modell segítségével, a már azonosított minták alapján képes feldolgozni a később betáplált adatokat.
(2) Az MI rendszer ezek után a következő módon működik: Először a rendszerbe újabb adatokat töltenek fel, amelyek hasonlóak a tanuláshoz használt adatokhoz. Ezek után a modell alapján az MI eldönti, hogy az új adat, mely megtanult mintázathoz hasonlít a leginkább.
(3) A rendszer végül informál arról, hogy milyen döntést hozott az elsajátított mintázatok alapján a belétáplált új adatokkal kapcsolatban. [17]
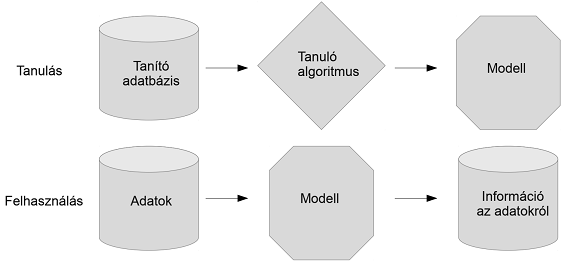
1. ábra: A gépi tanulás és tanulás során létrejövő modell felhasználásának lépései[18]
Jó példa a fenti logika alapján működő rendszerekre az önvezető autók fejlesztése, mivel az ilyen technológiák megfelelő működtetése nagy mennyiségű személyes adat feldolgozásával jár együtt. Az önvezető autót működtető szoftvernek ugyanis például tudnia kell különbséget tenni az utakon átkelő és járdákon közlekedő élő, emberi lények és élettelen tárgyak (pl. egy darab újságpapír, zacskó) között a balesetek elkerülése végett. Ezt az önvezető autót működtető szoftver fejlesztése során úgy érik el, hogy nagyon sok (több tíz, vagy akár százezer), emberekről készült képet, illetve videót elemeztetnek a rendszerrel, amely egy idő után megtanulja a hasonló fizikai, fiziológiai jellemzőik alapján, hogy az emberi élőlények hogyan néznek ki és hogyan mozognak. Később, ha esetleg az autó érzékel egy gyalogost a zebrán, úgy akkor is fel fogja ismerni, hogy egy emberi lény van előtte, ha a szoftver tanítása során nem is találkozott annak a személynek a képével.[19]
Fontos azt is megjegyezni, hogy a gépi tanulás során létrejövő modell nem feltétlenül tartalmazza a forrásadatokat, amelyek a tanulásának alapjául szolgáltak. A tanulás alapjául szolgáló adatoktól függetlenül is tud működni a legtöbb esetben a gépi tanulás során létrejött MI rendszer.[20]
Az emberi agynál a gépi tanulás jellemzően sokkal nagyobb mennyiségű nyers adatot kíván meg azért, hogy hatékonyan tudjon mintázatokat azonosítani és erre épülő döntési modelleket felállítani. Ezért elsőre azt is gondolhatjuk, hogy minél több adatunk van, annál jobb gépi tanuláson alapuló MI rendszereket tudunk készíteni. A gépi tanuláshoz használt adatok minősége és azok megfelelő előzetes kiválasztása és címkézése azonban sokkal fontosabb szempont. Már az adatok rendszerbe történő betöltése előtt tisztázni kell, hogy pontosan milyen feladat elvégzése céljából használjuk az adatokat és ezért a használt adatok körét a cél szempontjából relevánsokra szükséges korlátozni. A használt adatok jó megválogatása és előzetes kiválasztása így szintén fontos szempont.[21]
Lásd a következő példát: Egy USA-beli kórház a tüdőgyulladásban szenvedő betegekre jelentett kockázatokat kívánta kategorizálni egy erre a célra írt algoritmussal. A teszt során az a meglepő eredmény született, hogy a gyógyulás szempontjából legalacsonyabb kockázati besorolást a rendszer rendre azokra a páciensekre osztotta ki, akik a tüdőgyulladás mellett asztmában is szenvedtek. Ez annak volt köszönhető, hogy az ilyen betegek jellemzően sokkal gyorsabb és alaposabb ellátást kaptak, mint a töb-
- 672/673 -
biek, ezért gyorsabban fel is épültek. Ez a példa jól mutatja, hogy a nem megfelelően kiválasztott, vagy csak félinformációkat tartalmazó adatok felhasználása megtévesztő eredményeket produkálhat.[22]
Amennyiben a személyes adatok védelme szempontjából, a GDPR-ban is nevesített adattakarékosság elvét[23] használva próbáljuk meghatározni, hogy pontosan mennyi adatra van szükség a célnak megfelelő és hatékony gépi tanuláshoz, akkor a következő elvet fogalmazhatjuk meg: A gépi tanuláshoz először csak korlátozott mennyiségű tesztadatot szabad felhasználni. A tesztadatok feltöltése után folyamatosan monitorozni kell a rendszert, hogy az elérni kívánt cél szempontjából mennyire pontosan és hatékonyan működik. Amennyiben kevesebb adat is elég a megfelelő hatékonyság eléréséhez, úgy felesleges továbbiakat felhasználni.
A gépi tanulással kapcsolatban az egyik legtöbbször hangoztatott (nem csak adatvédelmi) aggály, hogy gyakran lehetetlen előre megjósolni, hogy milyen eredményt fog produkálni a rendszer. A használt modell produkálhat olyan eredményt is, amelyre látszólag semmilyen magyarázat nem létezik.[24] Ezt a jelenséget a gépi tanulásban "fekete doboz"-nak nevezik. Az egyszerű szemlélő számára a rendszer gyakorlatilag úgy működik, hogy a bemeneti oldalon adatokat kap, amelyek alapján megtanul valamit, majd produkál egy eredményt. Azt azonban rendkívül nehéz átlátni, hogy pontosan miért jutott erre az eredményre.[25]
Tudományos és műszaki területen a fekete doboz olyan készülék, rendszer vagy tárgy, amely kizárólag csak a bemenete, kimenete és átviteli jellemzői alapján vizsgálható, konkrét belső működése ismeretlen, azaz megvalósítása "átlátszatlan" (fekete). Szinte bármire lehet hivatkozni fekete dobozként: tranzisztorra, algoritmusra, vagy az emberi elmére. A fogalmat takaró jelenség leírása Wilhelm Cauertől eredeztethető, aki 1941-ben dolgozta ki az elméletét ezzel kapcsolatban, habár a fogalmat még nem használta. Később a követői írták le a jelenséget, úgy mint "fekete doboz" analízis.[26]
A fekete doboz ellentéte egy olyan rendszer, ahol a belső alkotórészek vagy logika hozzáférhetők a vizsgálat számára. Az ilyen rendszert időnként "fehér doboznak" is nevezik.

2. ábra: A fekete doboz sémája[27]
Az adatvédelem alapelvei között régóta szerepel a követelmény, hogy az érintett természetes személy számára (akinek az adatait kezelik) az adatkezelésnek átláthatónak kell lennie. Ezt az elvet a GDPR is kifejezetten nevesíti az 5. cikk (1) bekezdés a) pontjában. Ezek szerint a személyes adatok kezelését jogszerűen és tisztességesen, valamint az érintett számára átlátható módon kell végezni. A GDPR tehát a jogszerűség, a tisztességes eljárás és átláthatóság alapelveit egyszerre nevesíti, így azoknak minden adatkezeléssel kapcsolatban egymásra tekintettel és egyszerre kell érvényesülniük.
A kérdés ezért, hogy hogyan lehet úgy a gépi tanulást használó rendszereket létrehozni, hogy azok az érintett számára kellően átláthatóan működjenek az általuk produkált eredmények szempontjából, így a kezelt személyes adatok tekintetében megfeleljenek az átláthatóság követelményének.
A Norvég Adatvédelmi Hatóság jelentése szerint az átláthatóság szempontjából fontos szerepe van annak, hogy a használt gépi tanulórendszer milyen működési elvet használ. A jelentés itt példaként hivatkozik két működési elvre, az egyik az ún. döntési fa modell, a másik pedig a neurális hálózat modell.[28] A döntési fa a különböző döntési lehetőségeket ábrázolja, az esetleges következményeket, esélyeket, hasznosságot és erőforrásokat figyelembevéve, attól függően, hogy mire használják. A döntési fák matematikailag gráfok.[29]
- 673/674 -
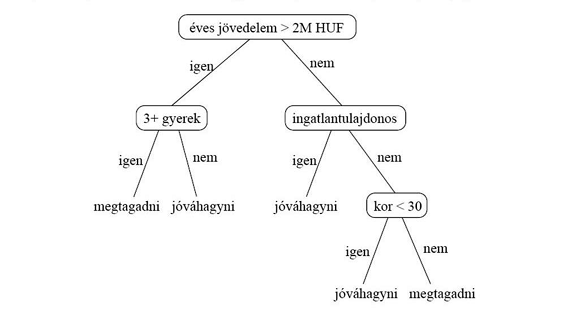
3. ábra: Döntési fa példa hitelbírálatra[30]
A neurális hálózat ehhez képest biológiai ihletésű döntésszimuláció. A neurális hálózatok rendszerint legalább három funkcionálisan és strukturálisan is jól elkülöníthető részből állnak: bemeneti réteg, rejtett rétegek és kimeneti réteg. A bementi réteg módosítás nélkül továbbítja a bemenetként átadott adatot a hálózat többi részének. Egy neurális hálózatnak több bemeneti rétege is lehet. A rejtett rétegek a bemenet és a kimenet között helyezkednek el, feladatuk az információ transzformációja, kódolása, illetve absztrakciók, köztes reprezentációk létrehozása. Számuk, típusuk, egymáshoz való kapcsolódásuk sorrendje és a bennük lévő neuronok száma változtatható paraméterei a hálózatnak. Végül a kimeneti réteg jelzi az eredményt. A kimeneti függvényt és a kimeneti neuronok számát az adott probléma jellege határozza meg.[31]
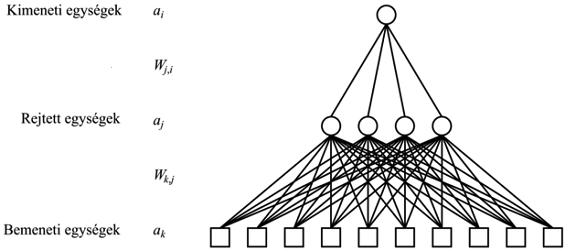
4. ábra: Egy többrétegű neurális hálózat modellje[32]
Mind a döntési fa, mind a neurális hálózat modellben az elágazások vagy rétegek száma rendszerenként változhat. Jó példa erre, hogy 2015-ben a Microsoft mérnökei megnyertek egy képfelismerő versenyt egy olyan neurális hálózat alkalmazásával, amely 152 rétegből állt.[33] A hálózat mérete és az egyes rétegek közötti kapcsolat olyan bonyolulttá teheti az adatkezelési folyamatokat, amelyeket megfelelő eszközök nélkül lehetetlen lenne az ember számára érthetően leírni. Az adatkezelés átláthatóságának jogi követelménye ezért komoly problémák elé állíthatja az MI megoldásokon alapuló adatkezelést fejlesztő vállalkozásokat.
A fő kérdés ezekkel az adatkezelési módszerekkel kapcsolatban, hogy vajon az átláthatóság elvének megfelel-e, ha csupán az MI szoftver által alkalmazott általános működési elvről tájékoztatja az adatkezelő az érintett személyt, vagy ennél sokkal részletesebb, a szoftver működésének technikai részleteibe is belemenő és a lehetséges eredmények felvázolását is megkísérlő tájékoztatás az elvárt, tehát ki kell-e nyitni a fekete dobozt? A GDPR szerinti megfelelő tájékoztatás elemzésére a tanulmány későbbi részeiben teszek kísérletet.
A Francia Adatvédelmi Hatóság (Commission nationale de l'informatique et des libertés, röviden: CNIL) 2017 decemberében hozott nyilvánosságra egy jelentést, amely az MI és az algoritmusok használata által felvetett néhány etikai kérdést vizsgál.[34] A jelentés a felelősséggel kapcsolatban felteszi a filozofikus kérdést, hogy az MI viselkedéséért vajon ki tehető felelőssé. Maga a jelentés egy orvosi példát hoz arra az esetre, amikor felmerülhet annak lehetősége, hogy magát az algoritmust tegyük felelőssé azokért a cselekedetekért, amelyeket elvégez.
A francia jog megköveteli, hogy egy betegséggel kapcsolatos diagnózist, csak orvos állapíthat meg. Amennyiben más végez ilyen tevékenységet az kuruzslásnak minősül, és mint jogellenes tevékenység, akár bűncselekmény elkövetésének gyanúját is felvetheti. Az orvosokat manapság viszont jónéhány esetben bonyolult szoftverek segítik a pontos diagnózis felállításában. A minél pontosabb diagnózist felállító szoftver ezért akár át is veheti az orvos tényleges szerepét, hiszen az ember hajlamos arra, hogy egy idő után csak formálisan elfogadja az algoritmus által hozott döntést. Ennek kapcsán merül fel magának a szoftvernek az esetleges "felelőssége" a döntéssel kapcsolatban.
Habár a jelentés konkrét javaslatot nem fogalmaz meg a felelősség kérdésével kapcsolatban, azt azért általánosságban megjegyzi, hogy a kritikus (jog)hatást kiváltó döntések meghozatalánál az lenne az ideális, ha az MI rendszerek biztosítanák az emberi beavatkozás és/vagy felül-
- 674/675 -
vizsgálat lehetőségét. A különösebben mélyebb megfontolást igénylő "tömegdöntéseknél" azonban meg lehetne hagyni a lehetőséget az algoritmus kezében. A CNIL tehát az MI használatával kapcsolatban a legnagyobb kihívást a döntések meghozatalában való alkalmazásuk mértékének ("scale of deployment") meghatározásában látja.[35]
Az emberi beavatkozás szükségessége megjelenik a GDPR előírásai között is. Ezek bemutatására a későbbiekben kerítek sort.
Az MI, ezen belül a gépi tanulás és a személyes adatok védelmének kapcsolatával az elmúlt időszakban több nemzetközi deklaráció is foglalkozott, amelyek alapvető követelményeket próbáltak felvázolni azzal kapcsolatban, hogy milyen adatvédelmi követelményekre kell figyelemmel lenni az ilyen rendszerek fejlesztése során. Az alábbiakban a legfrissebb két ilyen dokumentumot és főbb megállapításaikat tekintem át.
A strasbourgi székhelyű Európa Tanács 2019. január 25-én hozta nyilvánosságra iránymutatását a mesterséges intelligencia és az adatvédelem kapcsolatáról.[36]
A deklaráció általánosságban felhívja a figyelmet arra, hogy a személyes adatok kezelésével együtt járó MI fejlesztésnek az Európa Tanács ún. 108-as adatvédelmi egyezményével (illetve annak modernizált változatával) összhangban kell történnie.[37] A deklaráció nevesít olyan adatvédelemmel kapcsolatos alapelveket ennek megfelelően, mint jogszerűség, tisztességesség, célhoz kötöttség, szükségesség és arányosság, beépített és alapértelmezett adatvédelem, elszámoltathatóság, átláthatóság, adatbiztonság és kockázatalapú megközelítés. A dokumentum az érintetti jogok gyakorlásával kapcsolatban megfogalmazza, hogy annak feltétlenül kell érvényesülnie az MI-t használó adatkezelési megoldások kapcsán is. Az adatminimalizálás (adattakarékosság) elvének érvényesülésével kapcsolatban a dokumentum felhívja a fejlesztők figyelmét a szintetikus adatok használatának lehetőségére.[38] Ezenfelül bátorítja a fejlesztőket arra, hogy állítsanak fel különböző független testületeket, bizottságokat, amelyekkel konzultálni lehet az alapvető jogokra hatást gyakorló, szociális MI-k fejlesztése során felmerülő különböző jogi, etikai és társadalmi kérdésekben. A dokumentum szintén kitér az MI fejlesztések során a kockázatelemzés elvégzésének szükségességére, amely annak a társadalomra és alapvető jogokra, így különösen a személyes adatok védelméhez fűződő jogra gyakorolt hatását kell, hogy elemezze.
A dokumentum külön felsorolásban foglalkozik a jogalkotókra és döntéshozókra vonatkozó ajánlásokkal. Ezek többek között kiemelik, hogy az adatvédelmi felügyeleti hatóságoknak megfelelő erősforrásokkal és szakértelemmel kell rendelkezniük, hogy az MI fejlesztéssel és üzemeltetéssel összefüggő adatvédelmi ügyeket is hatékonyan tudják kezelni és kivizsgálni. Az ajánlás felhívja arra is figyelmet, hogy az MI általi döntéshozatal esetén fenn kell tartani az emberi felülbírálat jogát. Az MI fejlesztőknek pedig meg kell hagyniuk a lehetőséget, hogy konzultáljanak az adatvédelmi felügyeleti hatóságokkal, ha a technológiának jelentős hatása lenne az alapvető emberi jogokra és szabadságokra. Végül az adatvédelmi hatóságok közötti együttműködést és figyelemfelhívást, oktatást hangsúlyozza a deklaráció.
A már a tanulmány bevezetőjében is említett nyilatkozat szintén egy rövidebb, deklaráció jellegű dokumentum, amelyet 2018. október 23-án Brüsszelben fogadott el az évente megrendezendő nemzetközi adatvédelmi konferencia, az International Conference of Data Protection and Privacy Commissioners.[39]
A deklaráció összesen hat pontban emeli ki az MI fejlesztéssel kapcsolatos főbb problémákat, ezekre pedig felsorolásszintű javaslatokat fogalmaz meg. Az első pont a tisztességesség követelményére koncentrál. Ezen a követelményen belül kiemeli, hogy az MI rendszerek használata során az adatkezelésnek mindig összhangban kell állnia azzal az adatkezelési céllal, amely miatt a rendszert és az azt működtető MI-t eredetileg létrehozták. Ezen felül az MI használata során minden esetben figyelembe kell venni annak hatását az érintettekre, azok bizonyos csoportjaira, továbbá a társadalom egészére. Végül a felsorolás felhívja arra a figyelmet, hogy az MI-t használó rendszerek fejlesztését úgy kell végezni, hogy az elősegítse az emberiség fejlődését, és ne veszélyeztesse azt.
- 675/676 -
A második pont az elszámoltathatóság elvének való folyamatos megfelelést emeli ki, ezen belül megemlíti, hogy a releváns piaci szereplőknek és az érintetteknek fel kell hívni a figyelmét az MI fejlesztéséből és használatából fakadó problémákra, ebben pedig az adatvédelmi hatóságoknak is nagy szerep kell, hogy jusson. Az elszámoltathatóságnak való megfelelés különböző auditok, hatásvizsgálatok és időszakos felülvizsgálatok formájában is biztosítható. A fentieken túl az oktatás és kutatás fontosságát hangsúlyozza még a dokumentum ezen része.
A harmadik pont az átláthatóság követelményére koncentrál. Megemlíti, hogy az MI-t használó rendszerek működésének átláthatósága és így különösen az algoritmus működésének átláthatósága ("algorithmic transparency") és a megfelelő, az érintett számára érthető tájékoztatás kiemelt kérdés kell, hogy legyen a fejlesztés során. Az érintetti tájékoztatással kapcsolatban követelményként határozza meg a deklaráció, hogy a természetes személyeket mindig megfelelően tájékoztatni kell, ha éppen MI-t használó rendszert használnak és a személyes adataikat ilyen rendszernek adják meg feldolgozás céljából.
A negyedik pont a beépített és alapértelmezett adatvédelem elveinek való megfelelést emeli. Ezek szerint az MI-t használó rendszerek fejlesztése során folyamatosan figyelembe kell venni annak a személyes adatok kezelésére és az érintettekre jelentett hatását. Ezt folyamatosan dokumentálnia és igazolni is tudnia kell a fejlesztőnek. A beépített és alapértelmezett adatvédelem követelményének beemelése a dokumentumba egyértelműen a GDPR és az Európai Uniós adatvédelmi hatóságok hatására vezethető vissza, hiszen a GDPR 25. cikke már egyértelműen megnevezi és megfogalmazza ezeket az elveket és egységes követelményként fogalmazza meg azokat az adatkezelők részére.
A deklaráció ötödik pontja az érintetteket megillető jogok érvényesülésével foglalkozik. Ezek szerint az érintetteknek lehetővé kell tenni, hogy adott esetben gyakorolhassák az őket megillető, a személyes adatok kezeléséhez fűződő jogaikat, így a kezelt adataikról való tájékoztatáshoz, az adatokhoz való hozzáféréshez, azok törléséhez és a tiltakozáshoz fűződő jogokat. A deklaráció szintén kimondja, hogy biztosítani kell az érintettek részére a jogot, hogy felülvizsgálatot kérjenek a jogaikat jelentősen érintő olyan döntésekkel szemben, amelyeket egyébként eredetileg tisztán automatikus módon hozott meg egy algoritmus. Ez gyakorlatilag a GDPR-ban is szereplő - és a tanulmány későbbi részeiben részletesen is bemutatott - emberi beavatkozás kérésének megfogalmazása.
A hatodik pont végül az MI által feldolgozott adatok tekintetében az algoritmus által meghozott döntésekre terjeszti ki a diszkrimináció tilalmát. Felhívja a figyelmet, hogy szükséges olyan technológiai megoldások kidolgozása, amely azonosítani tudja és megfelelően csökkenteni a diszkriminációs problémákat az MI fejlesztés során. Ezenfelül az automatizált döntéshozatal során a személyes adatok naprakészségének és pontosságának garantálásán kívül a dokumentum szerint szükséges a szektor figyelmének felhívása az ilyen problémákra.[40]
A fentiekre tekintettel a konferencia szerint egy egységes nemzetközi szabályrendszert kell kidolgozni ebben az egész emberiséget érintő kérdésben. A konferencia erre tekintettel létrehozott egy állandó munkacsoportot, aminek a feladata az MI és adatvédelem kapcsolatának vizsgálata lesz.
A fentiekből is látszik, hogy az említett két viszonylag rövid deklaráció célja elsősorban inkább a figyelemfelhívás, mint konkrét problémák elemzése és ezekre egzakt válaszok adása. Általában felróható a hasonló nemzetközi deklarációkkal kapcsolatban, hogy a hangzatos kinyilatkoztatások és figyelemkeltés mellett nem sok hozzáadott értéket képviselnek a konkrét problémák megoldása szempontjából. Az ilyen típusú dokumentumok inkább mottószerűen hívják fel a figyelmet az MI és a személyes adatok kapcsolódási pontjaira, így általában túl sok konkrétumot nem tartalmaznak. A nemzetközi nyilatkozatoknak azonban általában nem is részletesség a célja, hanem hogy általánosságban hívják fel a figyelmet a jövő kulcskérdéseire, amikkel foglalkozni kell. Véleményem szerint mindenképpen üdvözlendő lenne a témában egy sokkal részletesebb és konkrétabb elemzés kibocsátása, azonban attól félek, hogy az első nagyobb horderejű MI és személyes adatok kapcsolatát érintő konkrét ügy és ahhoz kapcsolódó hatósági vizsgálat megindításáig erre még sajnos várnunk kell.
A gépi tanuláson alapuló rendszereket egyre gyakrabban használják személyes adatokkal kapcsolatos döntések meghozatalára. Az interneten megjelenő személyre szabott reklámok, hirdetések, és más tartalmak nagyon jó példák arra, hogy az emberi viselkedést elemző és abból tanuló algoritmusok hogyan működnek és hogyan használják a személyes adatainkat a minél személyesebb, célzott reklámok és tartalmak megjelenítésére. A profilalkotással szorosan összefügg az automatizált döntéshoza-
- 676/677 -
tal fogalma is, mivel az adott személlyel kapcsolatos minél egyedibb profil algoritmikus úton létrejött döntések mentén alakul ki. A személyre szabott reklámokon kívül a hitelbírálat elkészítése és vásárlói erő megjóslása során is gyakran fordul elő automatizált döntéshozatal és ahhoz kapcsolódóan profilalkotás. Ezekhez a döntésekhez a rendszereknek az optimális működés és döntéshozatal érdekében nagy mennyiségű és kellően pontos személyes adatra van szükségük.[41]
Az új európai uniós adatvédelmi rendeletben, a GDPR-ban az automatizált döntéshozatal és ezzel szoros összefüggésben a profilalkotás fogalmai már konkrétan megjelennek és ezekkel kapcsolatosan a rendelet különös előírásokat tartalmaz annak 22. cikkében.
Az Európai unió tagállamainak adatvédelmi felügyeleti hatóságait tömörítő, az Európai Adatvédelmi Testület jogelődjének tekinthető, ún. 29. cikk szerinti Adatvédelmi Munkacsoportja (röviden: WP29) 2017. október 3-án hozta nyilvánosságra az iránymutatását az automatizált döntéshozatallal és a profilalkotással kapcsolatban.[42] A továbbiakban a GDPR vonatkozó szabályozását mutatom be, majd azt veszem sorra, hogy vajon a jogszabályi követelmények hogyan alkalmazhatóak az MI és a gépi tanulás által felvetett adatvédelmi jogi problémákra.
A korábbi pontokban felvázolt gépi tanulórendszereket gyakran használják arra, hogy a felhasználók viselkedését elemezzék, és így felhasználói profilokat hozzanak létre. Egy adott felhasználóról alkotott profil olyan személyes jellemzőkről, személyiségjegyekről is adhat információt, amely alapján akár egyértelműen be lehet azonosítani egy adott embert.[43]
A profilalkotással kapcsolatban a GDPR tartalmaz egy fogalommeghatározást az értelmező rendelkezései között. Ezek szerint profilalkotásnak minősül a személyes adatok automatizált kezelésének bármely olyan formája, amely során a személyes adatokat valamely természetes személyhez fűződő bizonyos személyes jellemzők értékelésére használják. A fogalommeghatározás ide érti különösen a munkahelyi teljesítményhez, gazdasági helyzethez, egészségi állapothoz, személyes preferenciákhoz, érdeklődéshez, megbízhatósághoz, viselkedéshez, tartózkodási helyhez vagy mozgáshoz kapcsolódó jellemzők elemzését vagy előrejelzését.[44]
Habár elképzelhető, hogy klasszikus értelemben vett profilalkotást akár teljesen manuális módon is tud végezni egy adatkezelő, az ilyen tevékenységeket a rendelet nem vonja a fogalom alá. Profilalkotásnak tehát a GDPR fogalomrendszerében az automatizált személyes adatkezeléseken alapuló, vagy azt is használó tevékenységeket értjük. A profilalkotásnak magában kell foglalnia az automatizált adatkezelés valamilyen formáját, a WP29 iránymutatása szerint ez azonban nem zárja ki teljes mértékben az emberi beavatkozás lehetőségét.[45] Fontos, hogy a nem kizárólagosan automatizált döntések is magukban foglalhatnak profilalkotást.
A GDPR fogalomhasználata szempontjából meghatározó elem továbbá, hogy a profilalkotás célja egy természetes személy személyes jellemzőinek értékelése.
Az iránymutatás szerint ezért általánosságban elmondható, hogy a profilalkotás egy természetes személyről (vagy természetes személyek csoportjáról) való információgyűjtést és a jellemzőik vagy a viselkedési mintáik értékelését jelenti annak érdekében, hogy bizonyos kategóriába vagy csoportba sorolja őt (őket). A besorolás célja, hogy annak során elemezze az érintett érdeklődési körét, a tőle várható magatartást, vagy bizonyos képességeit.[46]
Ez a fogalom alkalmazható a gépi tanulást alkalmazó rendszerekre is, hiszen az ilyen rendszerekbe betöltött személyes adatok algoritmikus elemzése és azokból következtetések levonása irányulhat profilalkotási célokra is.
A gépi tanulás adatvédelmi elemzése szempontjából a másik kulcsfogalom az automatizált döntéshozatal. A vonatkozó uniós szabályozást vizsgálva azonban megállapíthatjuk, hogy sajnos sem a GDPR 22. cikke, sem a rendelet értelmező rendelkezései nem határozzák meg, hogy mi az automatizált döntéshozatal fogalma, holott több helyen is használja ezt a megfogalmazást a jogszabály.
A GDPR megfogalmazása több helyen együtt utal a profilalkotásra és az automatizált döntéshozatalra és közös szabályokat állapít meg velük kapcsolatban. Fontos megjegyezni, hogy ettől függetlenül a két fogalom nem azonos teljes mértékben. Létezhet olyan automatizált döntéshozatali eljárás, amely nem minősül egyben profilalkotásnak, illetve profilalkotást is lehet végezni automatizált döntéshozatali mechanizmusok beépítése nélkül. A legtöbb esetben azonban a két fogalom kéz a kézben járnak és kiegészítik egymást, így adatvédelmi szempontból indokolható az együttes tárgyalásuk. A WP29 iránymutatása ezt a kettősséget úgy fogalmazza meg, hogy az automatizált döntéshozatal hatóköre eltérő, és részben átfedheti a profilalkotást, vagy abból eredhet. Az iránymutatás szerint az automatizált döntéshozatal az a képes-
- 677/678 -
ség, hogy technológiai eszközök segítségével, emberi beavatkozás nélkül hoznak döntéseket.[47]
A kizárólag automatizált döntéshozatalban tehát nincs emberi részvétel a döntési folyamatban, amely jelenség témánk szempontjából megfeleltethető a gépi tanulás azon lépcsőjének, amikor a "fekete dobozban" lejátszódó folyamatok eredményeképpen megszületik a betöltött adatok kapcsán a döntés.
A továbbiakban a kizárólag automatizált egyedi döntéshozatalra vonatkozó előírásokat tekintem át, mivel a gépi tanulás érintettekre gyakorolt társadalmi hatása az ilyen adatkezeléseknél a legszembetűnőbb. Az ilyen adatkezelésekkel kifejezetten a GDPR 22. cikke is részletesen foglalkozik. A tanulmány a továbbiakban nem kíván foglalkozni az olyan esetekkel, amelyek nem kizárólag automatizált (tehát nem tisztán algoritmikus alapú) döntéshozatali folyamatokon alapulnak.
A GDPR 22. cikk (1) bekezdése alapján az érintett jogosult arra, hogy ne terjedjen ki rá az olyan, kizárólag automatizált adatkezelésen - ideértve a profilalkotást is - alapuló döntés hatálya, amely rá nézve joghatással járna vagy őt hasonlóképpen jelentős mértékben érintené. Ez a rendelkezés általános tilalmat állapít meg a kizárólag automatizált adatkezelésen alapuló döntéshozatal tekintetében. A rendelet ideérti az olyan profilalkotást is, amely ilyen döntési folyamatokon alapul. Ez a tilalom attól függetlenül fennáll, hogy az érintett tesz-e intézkedést a személyes adatai kezelésével kapcsolatban. Főszabályként tehát a GDPR általános tilalmat állít fel a joghatással vagy hasonlóképpen jelentős hatással járó, kizárólag automatizált egyedi döntéshozatalra.[48]
A 22. cikk tilalomként, és nem érvényesíthető jogként való értelmezése azt jelenti, hogy a természetes személyeket automatikusan védik azoktól a hatásokból, amelyekkel az ilyen adatkezelés esetleg járhat.[49]
Ahhoz, hogy a döntés tekintetében emberi részvételnek minősüljön egy tevékenység és ezért ne kelljen rá alkalmazni a 22. cikk általános tilalmát, az adatkezelőnek biztosítania kell, hogy a döntést érintő emberi áttekintés érdemi legyen, és nem csak jelképes gesztus. Olyan személynek kell végeznie, aki jogkörrel és kompetenciával rendelkezik a döntés megváltoztatására. Az elemzés részeként az összes releváns adatot figyelembe kell venni.[50] A tilalom feloldásához tehát a végső döntést embernek kell meghoznia, vagy az algoritmus által felajánlott döntést mérlegelnie és jóváhagynia.
A tisztán automatizált döntéshozatalra vonatkozó szabályokat továbbá csak azokban az esetekben kell alkalmazni, amikor az joghatással, vagy hasonló jelentős hatással jár az érintett természetes személyre nézve. A GDPR nem határozza meg a "joghatás" vagy a "hasonlóképpen jelentős" fogalmakat, azonban a rendelet ezen megfogalmazása egyértelművé teszi, hogy a 22. cikk csak a súlyos következményt jelentő hatásokra terjed ki.[51]
A joghatás megköveteli, hogy a gépi döntés befolyásolja valaki törvényes jogait. Joghatás lehet olyasmi is, ami befolyásolja a személy jogállását vagy szerződésen alapuló jogait. A WP29 szerint az ilyen jellegű hatásra való példák közé tartoznak a természetes személyekre vonatkozó azon automatizált döntések, amik eredményeként: szerződést mondanak fel, a törvény által biztosított szociális ellátást - például gyermekkel kapcsolatos vagy lakhatási támogatást - ítélnek oda vagy tagadnak meg, megtagadják a belépést egy országba vagy megtagadják az állampolgárságot.[52]
Az automatizált döntéshozatal hatása az emberek törvényben, vagy szerződésben lefektetett jogaira viszonylag egyértelműen körülhatárolható eseteket érint. Emellett azonban megjelenik a homályosabban megfogalmazott "hasonlóképpen jelentős" hatás fogalma is a GDPR 22. cikkében, mint szintén a tiltás alá eső körülmény.
A GDPR (71) preambulumbekezdése tartalmazhat ezzel a fogalommal kapcsolatban némi fogódzót, amely az alábbi példákat sorolja fel: "egy online hitelkérelem automatikus elutasítása" vagy "emberi beavatkozás nélkül folytatott online munkaerő-toborzás".
Nehéz pontosan meghatározni, hogy mit kell kellően jelentős mértékűnek tekinteni ahhoz, hogy elérje a küszöböt, azonban a WP29 szerint a következő döntések ebbe a kategóriába tartozhatnak: Az egyén anyagi körülményeit befolyásoló döntések, például a hitelre való jogosultságát illetően; olyan döntések, amelyek befolyásolják az egyén egészségügyi szolgáltatásokhoz való hozzáférését; olyan döntések, amelyek megtagadnak valakitől egy foglalkoztatási lehetőséget, vagy valakit súlyos hátránynak tesznek ki; döntések, amelyek befolyásolják valakinek az oktatáshoz való hozzáférését, például: egyetemi felvétel.[53]
A WP29 szerint az online fogyasztói profilok felépítésén alapuló célzott reklámra vonatkozó automatikus döntésnek legtöbbször nem lesz hasonlóan jelentős mértékű hatása a természetes személyekre (pl. ruházati hirdetések). Ebben a kategóriában is vannak azonban olyan adatkezelések, amelyek jelentős hatást gyakorolhatnak a társadalom bizonyos csoportjaira, így a kiszolgáltatott helyzetű felnőttekre. Például ha a felállított profil alapján egy személy valószínűsíthetően pénzügyi nehézségekkel küzd, és őt mégis rendszeresen magas kamatozású hitelekről szóló hirdetésekkel veszik célba, akkor potenciálisan további adósságot halmoz fel (feltéve, ha elfogadja
- 678/679 -
az ilyen ajánlatokat).[54] Az ilyen esetekre már vonatkozik a 22. cikkben megfogalmazott általános tilalom. Fő szabály szerint így egy anyagi nehézségekkel küzdő fogyasztóról (gépi tanulással) alkotott profilt nem lehet azon célból felhasználni, hogy őt további anyagi kockázatvállalásra próbálják célzottan rávenni. Nem hivatkozhatnak arra az adatkezelést végző profilalkotók, hogy a hitel felvétele tőlük függetlenül az érintett döntése, mivel a profilalkotás - amelyen a fogyasztói döntés alapul - sem jogszerű.
A fent írtak szerint a 22. cikk (1) bekezdése általános tilalmat rendel a joghatással vagy hasonlóképpen jelentős hatással járó kizárólag automatizált egyedi döntéshozatallal szemben. Léteznek azonban kivételek ezen általános tilalom alól, amelyeket a 22. cikk (2) bekezdése nevesít. Ezek szerint a tilalom nem alkalmazható abban az esetben, ha a döntés:
(1) az érintett és az adatkezelő közötti szerződés megkötése vagy teljesítése érdekében szükséges;
(2) meghozatalát az adatkezelőre alkalmazandó olyan uniós vagy tagállami jog teszi lehetővé, amely az érintett jogainak és szabadságainak, valamint jogos érdekeinek védelmét szolgáló megfelelő intézkedéseket is megállapít; vagy
(3) az érintett kifejezett hozzájárulásán alapul.
Az első kivétel a szerződés teljesítése, amely alapján egy szerződés kapcsán létrejövő jogviszonyban az adatkezelők alkalmazhatnak automatizált döntéshozatali folyamatokat a szerződéssel összefüggő célokra. A WP29 szerint ebben az esetben az adatkezelőnek be kell tudnia mutatni, hogy az automatizált döntéshozatal alkalmazása a legmegfelelőbb adatkezelési módszer a szerződésben meghatározott célok eléréséhez. Ha a szerződéssel elérni kívánt célt más módszerrel is el lehet érni, az már nem minősül szükségesnek.
A második kivétel, ha az automatizált döntéshozatal lehetőségét az adott adatkezeléssel kapcsolatban az uniós vagy tagállami jog teszi lehetővé. A vonatkozó jogszabálynak az érintettek jogait és szabadságait, valamint jogos érdekeit védő megfelelő intézkedéseket is meg kell határoznia. A GDPR (71) preambulumbekezdése szerint ilyen lehet például, ha a jog a csalás és adóelkerülés megelőzése érdekében lehetővé teszi az állam számára, hogy automatizált döntéshozatali mechanizmusokat alkalmazzon.
Végül a harmadik kivétel, ha az automatizált döntéshozatal alkalmazása az érintett kifejezett hozzájárulásán alapul.[55]
Maga a GDPR nem határozza meg a "kifejezett hozzájárulás" fogalmát, azonban a WP29 egy másik, a hozzájárulással kapcsolatos iránymutatása útmutatást ad annak értelmezéséről az alábbiak szerint.
A hozzájárulás kifejezett voltáról való meggyőződés legegyértelműbb módja a hozzájárulás írásbeli nyilatkozatban történő megerősítése. Az aláírt nyilatkozat azonban nem az egyetlen módja a kifejezett hozzájárulás megszerzésének. A WP29 szerint digitális vagy online kontextusban például előfordulhat, hogy az érintett elektronikus űrlap kitöltésével, elektronikus levél küldésével, az aláírását tartalmazó szkennelt dokumentum feltöltésével vagy elektronikus aláírás használatával is ki tudja állítani az előírt nyilatkozatot. Ez szintén megfelelhet a kifejezett hozzájárulás követelményének. Elméletileg akár szóbeli nyilatkozatok használata is kellően egyértelmű lehet az érvényes, kifejezett hozzájárulás megszerzéséhez. Az adatkezelő az ilyen esetekben viszont jellemzően nehezen tudja bizonyítani, hogy a nyilatkozat rögzítésekor az érvényes, kifejezett hozzájárulás minden feltétele teljesült, így inkább az írásbeli, vagy más formában rögzített alak az ajánlott formája a kifejezett hozzájárulás beszerzésének. Végül a hozzájárulás kétlépcsős ellenőrzésével is meg lehet győződni a kifejezett hozzájárulás érvényességéről (ilyenre jó példa a kétfaktoros autentikáció használata).[56]
A GDPR tájékoztatási kötelezettséget ír elő az adatkezelő részére a kizárólag automatizált adatkezelésen alapuló, joghatással vagy hasonlóan jelentős hatással járó döntéshozatallal kapcsolatban. A rendelet beleérti ebbe a körbe az ilyen adatkezelésen alapuló profilalkotást is.[57] Ennek keretében a következő három információt kell közölni az érintettel:
(1) Tájékoztatni kell az ilyen típusú adatkezelés tényéről;
(2) érdemi tájékoztatást kell adni az alkalmazott logikáról;
(3) és végül arról is, hogy az adatkezelés milyen jelentőséggel és milyen várható következményekkel bír az érintettre nézve.[58]
Az automatizált egyedi döntéshozatal tényének közlése viszonylag egyszerű követelmény, ennek keretében elég, ha az adatkezelő arról tájékoztat, hogy ilyen típusú adatkezelésre kerül sor. Fontos, hogy az érintett arról is tudomással bírjon, ha az automatizált egyedi döntéshozatal kapcsán egyben profilalkotásra is sor kerül.
- 679/680 -
Az alkalmazott logikáról való tájékoztatás mikéntje már több kérdést vet fel. Ez főleg az előző pontokban bemutatott gépi tanulási módszerek esetében jelenthet nagy kihívást az adatkezelő részére, mivel az sokszor rendkívül összetett, nagyon nehezen átlátható adatkezelési folyamatokon alapul. Lásd erre kiváló példaként a fekete doboz jelenséget.
A GDPR szerint az adatkezelőknek "érdemi információt" kell adniuk az alkalmazott logikáról. Önmagában így például nem lehet elég az, ha az adatkezelő csak általánosságban közli, hogy neurális hálózaton alapuló rendszert üzemeltet, mivel az érintett így érdemben vajmi keveset fog felfogni arról, hogy mi történik az adatkezelés során a személyes adataival.
Az érdemi információ viszont azt sem jelenti, hogy feltétlenül bonyolult magyarázatot kell nyújtania az alkalmazott algoritmusokról vagy az algoritmust teljes egészében fel kellene tárnia az adatkezelőnek. A technológia részletes bemutatása ugyanis a legtöbb esetben lerontaná a tájékoztatás közérthetőségét és hátráltatná a befogadását.[59] A technológia komplexitása természetesen nem lehet mentség a tájékoztatás teljes mellőzésére sem. Pont ezekben az esetekben érhető tetten leginkább az érintetti tájékoztatás jogintézményének valódi célja és fontossága. A GDPR szellemiségéből is az következik, hogy a személyes adataikat érintő bonyolultabb adatkezelések lényegével és hátterével is tisztában kell lenniük az érintetteknek.
A korábbi pontokban ismertetett gépi tanulás és a "fekete doboz" problémája azonban a fentiek ellenére a tájékoztatás kapcsán első ránézésre szinte megoldhatatlan problémának tűnhet az adatkezelők számára. Mégis hogyan tájékoztassa érdemben az MI használója, üzemeltetője az érintettet, amikor pontosan nem is tudja, hogy mi történik az adatokkal a fekete dobozban?
Az Oxford Internet Institute és a londoni Alan Turing Institute közös kutatása szerint az algoritmusok által hozott döntések és azokhoz kapcsolódó adatkezelések átláthatósága szempontjából jó gyakorlat lehet, ha az adatkezelő lehetőséget biztosít az érintettnek, hogy ún. "alternatív értelmezések" kapcsán ismerhesse meg az adatkezelés működését. Ennek oka, hogy az érintetteket legtöbbször nem is igazán érdekli, hogy maga a logika hogyan működik, hanem inkább az, hogy ők maguk hogyan tudnak javítani az algoritmus által megállapított eredményen.[60]
Erre az alábbi példát hozza a brit intézetek kutatását bemutató tanulmány: Egy hitelkérelem elbírálása során az alkalmazott kockázatelemző szoftver arra a következtetésre jut, hogy az érintett nem kaphatja meg a hitelt. Ebben az esetben, ha az érintett tájékoztatást kér arról, hogy mi az alkalmazott logika alapján a negatív elbírálás oka, úgy az információ, hogy a szoftver milyen általános logika alapján működik és jut többek között ilyen következtetésre, számára nem sok plusz információt hordoz. Sokkal érdemibb tájékoztatás lehetne részére, ha rendelkezésére állna egy nyilvános tesztrendszer, amit akár fiktív adatokkal kitöltve használhatnak az érintettek. Így elegendő és érdemi információt kaphatnak arról, hogy az alkalmazott rendszer a belétáplált adatok alapján milyen következtetésekre jut. A tanulmány szerint a megoldás azért is előnyös, mivel tiszteletben tartja az MI fejlesztőjének üzleti titokhoz és szellemi tulajdonhoz fűződő jogosultságait is.[61] Ezt a fajta megoldást használta fel például a Google a TensorFlow elnevezésű gépi tanulási rendszerénél is.[62]
A fentieken túl meg kell még említeni, hogy az adatkezelőnek az adatkezelés "jelentőségéről" és a "várható következményeiről" is tájékoztatnia kell az érintettet. A WP29 iránymutatása szerint ahhoz, hogy ez az információ érdemi és érthető legyen, a lehetséges hatásokra vonatkozó valós és kézzelfogható példákat kell megadni. Digitális kontextusban az adatkezelők további eszközöket is használhatnak az ilyen hatások bemutatására és vizuális technikákat vehetnek igénybe egy korábbi döntésük meghozatalának magyarázatához is. Az iránymutatás ebben az esetben - a brit tanulmányhoz hasonlóan -, összehasonlító alkalmazás biztosítását hozza fel példaként.[63] Tehát a tájékoztatás során nem kell a "fekete dobozt" kinyitnia az adatkezelőnek az érintett előtt, elég ha megérteti vele, hogy a döntés meghozatala hogyan történt, és ő mit tehet annak érdekében, hogy ügyében más (kedvezőbb) döntés szülessen.[64]
Ezek az értelmezések véleményem szerint gyakorlatilag aláhúzzák azt, hogy egy tesztrendszer elérhetővé tétele nem csak az alkalmazott logika, hanem az érintettre vonatkozó hatás és jelentőség demonstrálására is jó megoldás.
A GDPR előírásai alapján az adatkezelő köteles lehetővé tenni az érintett számára, hogy emberi beavatkozást kérjen az őt érintő automatizált egyedi döntéshozatallal kapcsolatban. A lehetőséget az adatkezelőnek kell biztosítania.[65]
Ebben az esetben tehát lehetővé kell tenni a döntéshozatal menetének emberi felülvizsgálatát, valamint - adott esetben - a döntés módosítását is az esetleges téves következtetések, hibák kiküszöbölése érdekében. Az érintett jogosult kifejteni az álláspontját a döntéssel kapcsolatban és kifogást is benyújthat az őt érintő hibás döntés orvoslása céljából.[66]
A WP29 iránymutatása kiemeli, hogy az emberi beavatkozást olyan személynek kell végeznie, aki megfelelő jogkörrel és képességgel rendelkezik a döntés megváltoz-
- 680/681 -
tatására. A felülvizsgálónak alaposan meg kell vizsgálnia az összes releváns adatot, ideértve az érintett által rendelkezésre bocsátott minden további információt. Mind az iránymutatás, mind a GDPR magyar kommentárja kiemeli ezenfelül azt, hogy a döntéshozatal emberi felülvizsgálatának az is lehet az egyik célja, hogy a döntés eredménye alapján az érintett ne legyen kitéve hátrányos megkülönböztetésnek.[67] A hátrányos megkülönböztetés tilalmával kapcsolatban általános gyakorlati megoldásként periodikus ellenőrző, "auditáló" algoritmusok beépítését javasolja az iránymutatás, bár konkrét példát sajnos nem hoz.[68]
Az emberi beavatkozás kérésének teljesítése a gyakorlatban sok kérdést vet fel az MI alapú döntési rendszerek használata kapcsán. Egyes kritikák szerint ezt nagyon nehéz lehet kivitelezni, például olyan szolgáltatások igénybevételénél, amelyek dinamikus árképzési rendszert használnak.[69] Véleményem szerint - a példánál maradva - amikor egy ilyen szolgáltatást igénybe vesz a felhasználó és dinamikus árképzéssel kikalkulált vételárat elfogadja, úgy a szerződés létrejötte és a vételár átutalása után az emberi beavatkozás kérése a legtöbbször már a szerződéses rendelkezések miatt is kizárható. Az ilyen esetekben ezért reálisan inkább még a szerződés létrejötte előtt lenne lehetőség az emberi beavatkozásra, hiszen a személyes adatok alapján meghozott döntés (az ár kikalkulálása az érintett profilja alapján) már annak elfogadása előtt megszületik és rendelkezésre áll.
Véleményem szerint az emberi beavatkozás kérésének gyakorlása során a döntéshozatali mechanizmusok felülvizsgálatát az érintettre gyakorolt hatás szemszögéből kell megközelíteni. Meg kell tehát vizsgálnia az emberi beavatkozásra kijelölt személynek, hogy pontosan milyen adatok voltak érintettek a döntéshozatalban és hogy milyen döntés született, majd ezt összevetnie az érintett által előterjesztett kifogásokkal. Ez ebben az esetben sem igényli a "fekete doboz" felnyitását, így a döntés mögött meghúzódó algoritmikus folyamat aprólékos feltárását és megértését. Erre a legtöbb esetben nem is lenne valós lehetősége a felülvizsgálatra jogosult személynek, hiszen - mint már az előzőekben is kifejtésre került - az adatokon végzett matematikai műveletek egy bizonyos szint után az emberi szemlélő számára követhetetlenek lesznek. A felülvizsgálatra jogosult személynek tehát azt kell elsősorban mérlegelni, hogy a döntésnek vajon ugyanez lett volna-e az eredménye, ha azt nem egy algoritmus végzi.
A tanulmányban arra kerestem a választ, hogy vajon az MI, ezen belül pedig a gépi tanulási folyamatok milyen problémákat vetnek fel a személyes adatok védelme szempontjából. Az előzőekben az érintett szemszögéből nézve az átláthatóság, a személyes adatok célhoz kötött, adattakarékos felhasználása és az emberi beavatkozás lehetősége szempontjából vizsgáltam a problémát. Az alábbiakban egy felsorolással próbálom meg kiemelni azon fő tételeket, amelyeket a gépi tanuláson alapuló MI rendszerek fejlesztése során - a GDPR 25. cikkében nevesített beépített és alapértelmezett adatvédelem elvének való megfelelés céljából - mindenképpen figyelembe kell venni a jogszerűség garantálása érdekében.
(1) Gépi tanuláson alapuló, automatikus döntések meghozatalára képes rendszer üzemeltetése során az üzemeltető adatkezelőnek megfelelő jogalapot kell igazolnia a kezelt személyes adatok tekintetében. Ennek hiányában ilyen rendszer üzemeltetése tilos.
(2) A gépi tanuláson alapuló rendszer fejlesztése során a lehető legkevesebb személyes adatot kell felhasználni a teszteléshez. A rendszer hatékonyságát folyamatosan monitorozni kell és csak az optimális hatékonyság elérése érdekében szabad több személyes adatot a rendszerbe tölteni.
(3) A már aktív, valós személyes adatokat felhasználó rendszer átláthatóságát úgy kell ideális esetben biztosítani, hogy "alternatív döntések" kidolgozására való tesztrendszert kell biztosítani az érintettek részére. Ezt a rendszert használva az érintettek saját maguk fedezhetik fel az MI működése során alkalmazott logikát.
(4) Az érintett részére biztosítani kell az emberi beavatkozást a kizárólag algoritmikus alapon létrejövő döntésekkel kapcsolatban. A felülvizsgálatra jogosult személynek azt kell elsősorban mérlegelni, hogy a döntésnek vajon ugyanez lett volna-e az eredménye, ha azt nem egy algoritmus végzi. A döntés felülvizsgálata során az érintett részéről megadott személyes adatok és a gépi tanulórendszer működésének célját kell elsősorban figyelembe venni.
Az MI és a gépi tanulás jogszerűségének adatvédelmi szempontú megítélésére a fenti felosztást dolgoztam ki, amely a jogalap és a célhoz kötöttség mellett elsősorban az átláthatóság és az emberi beavatkozás szempontjából fogalmaz meg követelményeket. Ezen kritériumrendszernek véleményem szerint minden esetben meg kell felelnie az automatizált döntés meghozatalára képes azon rendszernek, amely személyes adatok elemzése kapcsán hoz döntéseket az érintettre nézve.
Tisztában vagyok azzal, hogy kidolgozhatóak más felosztások is, például más alapjogokra gyakorolt hatás szempontjából. Ilyen például a hátrányos megkülönböztetés tilalmának vizsgálata, amire azonban részletesen jelen tanulmányban nem kívántam kitérni. Ettől függetlenül remélem, hogy az írással hozzájárultam a téma tudományos feldolgozásához és a diskurzus erősítéséhez a területen. ■
JEGYZETEK
[1] A szerző jogász, a Nemzeti Adatvédelmi és Információszabadság Hatóság főosztályvezető-helyettese. Tudományos doktori (PhD) fokozatát a Pécsi Tudományegyetemen szerezte 2015-ben a virtuális tulajdonról írt disszertációjával.
[2] Fan Hui, többszörös európai Go bajnok reagált így, amikor látta, hogy a Google által kifejlesztett, mélytanuló algoritmusokon alapuló AlphaGo szoftver milyen szokatlan lépést játszott meg egy Go meccsen. Lásd: https://www.wired.com/2016/03/sadness-beauty-watching-googles-ai-play-go/ [2019. 05. 166.]
[3] 40th International Conference of Data Protection and Privacy Commissioners: Declaration on Ethics and Data Protection in Artificial Intelligence. Brüsszel, 2018. október 23. Elérhető: https://icdppc.org/wp-content/uploads/2018/10/20180922_ICDPPC-40th_AI-Declaration_ADOPTED.pdf [2019. 02. 03.]
[4] Siba László (szerk.): Oxford számítástechnikai értelmező szótár. Novotrade Kiadó, 1989.
[5] https://www.coe.int/en/web/artificial-intelligence/glossary [2019. 02. 21.]
[6] John McCarthy - Marvin Minsky - Nathaniel Rochester - Claude Shannon: Proposal for the Dartmouth Summer Research Project on Artificial Intelligence. In: Tech. rep., Dartmouth College, 1955.
[7] Kollár Csaba: A mesterséges intelligencia kapcsolata a humán biztonsággal. In: Nemzetbiztonsági Szemle, 2018/1. p. 10.
[8] Stuart J. Russell - Peter Norvig: Mesterséges Intelligencia - Modern megközelítésben. Panem Könyvkiadó, Budapest, 2000. 26. fejezet, Online: http://project.mit.bme.hu/mi_almanach/books/aima/index [2019. 02. 03.]
[9] Csáji Balázs Csanád: A mesterséges intelligencia filozófiai problémái. Szigorlati dolgozat, Eötvös Lóránd Tudományegyetem, filozófia szak. Budapest (2002) p. 4. Forrás: http://old.sztaki.hu/~csaji/CsBCs_MI.pdf [2019. 05. 27.]
[10] Ulrike Barthelmess - Ulrich Furbach: Do We Need Asimov's Laws? In: Lecture Notes in Informatics, Gesellschaft für Informatik, Bonn, 2014. p. 5.
[11] Ray Kurzweil: A szingularitás küszöbén. Ad Astra Kiadó, 2014.
[12] Stuart J. Russell - Peter Norvig: i. m. 26. fejezet
[13] Datatilsynet: Artificial intelligence and privacy. Report, January 2018. Online: https://www.datatilsynet.no/globalassets/global/english/ai-and-privacy.pdf [2019. 03. 30.]
[14] Szepesvári Csaba: Gépi tanulás - rövid bevezetés. Előadás, MTA SZTAKI, 2005. március 22. Online: http://old.sztaki.hu/~szcsaba/talks/lecture1.pdf [2019. 04. 06.]
[15] Lásd pl.: https://www.technologyreview.com/s/513696/deep-learning/ [2019. 02. 22.]
[16] Hlács Ferenc: AI: a nem emberi intelligencia már velünk van? 1. rész. 2016. június 20. Online: https://www.hwsw.hu/hirek/55760/ai-mesterseges-intelligencia-gepi-tanulas-machine-deep-learning.html [2019. 04. 06.]
[17] Datatilsynet: i. m., p. 7.
[18] Forrás: Kocsis Márton: Gépi tanulás a gyakorlatban. Előadás diasor. Online: http://docplayer.hu/11459797-Gepi-tanulas-a-gyakorlatban-bevezetes.html [2019. 05. 22.]
[19] Lásd pl. a budapesti székhelyű AImotive által fejlesztett, jelenleg tesztelés alatt álló önvezető autó rendszert. Honlap: https://aimotive.com/ [2019. 02. 21.]
[20] Datatilsynet: i. m., p. 10.
[21] Datatilsynet: i. m., p. 11.
[22] The Royal Society: Machine learning: the power and promise computers that learn by example. 2017, p. 93. https://royalsociety.org/~/media/policy/projects/machine-learning/publications/machine-learning-report.pdf [2019. 04. 07.]
[23] GDPR 5. cikk (1) bekezdés c) pont: A személyes adatok az adatkezelés céljai szempontjából megfelelőek és relevánsak kell, hogy legyenek, és a szükségesre kell korlátozódniuk ("adattakarékosság").
[24] Datatilsynet: i. m., p. 12.
[25] Infotstart: Belenéztek a fekete dobozba az ELTE kutatói. 2018. 11. 16. https://infostart.hu/tudomany/2018/11/16/melytanulasi-halozatot-vizsgaltak-az-elte-kutatoi [2019. 04. 07.]
[26] E. Cauer - W. Mathis - R. Pauli: Life and Work of Wilhelm Cauer (1900-1945). In: Proceedings of the Fourteenth International Symposium of Mathematical Theory of Networks and Systems (MTNS2000), p. 4., Perpignan, June, 2000.
[27] Forrás: https://hu.wikipedia.org/wiki/F%C3%A1jl:Feketedoboz.png [2019. 05. 27.]
[28] Datatilsynet: i. m. pp. 13-14.
[29] Lásd: Mesterséges intelligencia elektronikus almanach. BME projekt, 2009. TAMOP - 4.1.2-08/2/A/KMR-2009-0026. http://project.mit.bme.hu/mi_almanach/books/aima/ch18s03 [2019. 04. 18.]
[30] Forrás: Dr. Bodon Ferenc: Adatbányászati algoritmusok. http://www.cs.bme.hu/~bodon/magyar/adatbanyaszat/tanulmany/adatbanyaszat.pdf [2019. 04. 18.]
[31] Mesterséges intelligencia elektronikus almanach. i. m.
[32] Forrás: Mesterséges intelligencia elektronikus almanach. i. m.
[33] Lásd: https://blogs.microsoft.com/ai/microsoft-researchers-win-imagenet-computer-vision-challenge/ [2019. 04. 18.]
[34] CNIL: How can humans keep the upper hand? The ethical matters raised by algorithms and artificial intelligence. 2017. Online: https://www.cnil.fr/sites/default/files/atoms/files/cnil_rapport_ai_gb_web.pdf [2019. 03. 30.]
[35] CNIL: i. m. p. 30.
[36] Council of Europe (Európa Tanács): Guidelines on Artificial Intelligence and Data Protection. T-PD(2019)01, Stasbourg, 2019. január 25. https://rm.coe.int/guidelines-on-artificial-intelligence-and-data-protection/168091f9d8 [2019. 02. 22.]
[37] Az egyének védelméről a személyes adatok gépi feldolgozása során, Strasbourgban, 1981. január 28. napján kelt egyezmény (Magyarországon kihirdette: 1998. évi VI. törvény). ETS 108
[38] Az OECD által kiadott Statisztikai szójegyzék alapján a szintetikus adat fogalma olyan megközelítéseket takar, amelyek alapján a bizalmasságot a valós adatokból mesterségesen generált (konkrét személyhez nem köthető) szintetikus adatok felhasználásával igyekeznek garantálni. Lásd: OECD: Glossary of statistical terms, 2007. https://ec.europa.eu/eurostat/ramon/coded_files/OECD_glossary_stat_terms.pdf [2019. 02. 22.]
[39] A konferencia honlapja: https://icdppc.org/ [2019. 05. 20.]
[40] A New York Egyetemen belül működő AI Now Institute 2018 évi éves jelentése is felhívja a figyelmet az MI fejlesztés és a diszkrimináció tilalmának problémájára. A jelentés hivatkozik néhány olyan kutatásra, amely alapján kiderült, hogy amennyiben az MI szoftver "tanítására" olyan adatokat használnak, amelyek hátrányosan állítanak be bizonyos társadalmi csoportokat, úgy az MI is hajlamos lesz inkább hátrányosan megkülönböztető döntéseket hozni ezen csoportokkal kapcsolatban. Lásd: AI Now Institute: AI Now Report 2018. New York University, 2018. december. pp. 24-27., 37-39. Online: https://ainowinstitute.org/AI_Now_2018_Report.pdf [2019. 03. 14.]
[41] 29. cikk szerinti Adatvédelmi Munkacsoport (WP29): Iránymutatás az automatizált döntéshozatallal és a profilalkotással kapcsolatban 2016/679 rendelet alkalmazásához (WP251rev.01), 2017. október 3. http://naih.hu/files/wp251rev01_hu.pdf [2019. 04. 19.], p. 5.
[42] WP29 (2017): i. m.
[43] Péterfalvi Attila - Révész Balázs - Buzás Péter (szerk.): Magyarázat a GDPR-ról. Budapest, 2018. Wolters Kluwer Hungary Kft. p. 198.
[44] GDPR 4. cikk 4. pont
[45] WP29 (2017): i. m., p. 7.
[46] WP29 (2017): i. m., p. 8.
[47] WP29 (2017): i. m., p. 8.
[48] Michael Veale - Lilian Edwards: Clarity, surprises and further questions in the Article 29 Working Party draft guidence on automated decision making and profiling. Computer, Law and Security Review 34 (2018). p. 400.
[49] Michael Veale et. al.: i. m., p. 400.
[50] WP29 (2017): i. m., p. 22.
[51] Michael Veale et. al.: i. m., p. 401.
[52] WP29 (2017): i. m., p. 22.
[53] WP29 (2017): i. m., p. 23.
[54] WP29 (2017): i. m., p. 24.
[55] WP29 (2017): i. m., p. 25.
[56] 29. cikk szerinti Adatvédelmi Munkacsoport (WP29): Iránymutatás az (EU) 2016/679 rendelet szerinti hozzájárulásról (WP259rev.01.), 2018. április 10. http://naih.hu/files/wp259-rev-0_1_HU.PDF [2019. 05. 11.] pp. 20-22.
[57] GDPR 15. cikk (1) bekezdés h) pont
[58] GDPR 13. cikk (2) bekezdés f) pont
[59] Péterfalvi Attila et. al.: i. m., p. 158.
[60] Sandra Wachter - Brent Mittelstadt - Chris Russell: Counterfactual Explanations Without Opening the Black Box: Automated Decisions and the GDPR (October 6, 2017). Harvard Journal of Law & Technology, 31 (2), 2018. pp. 863-871.
[61] Sandra Wachter et. al.: i. m., p. 844.
[62] https://www.tensorflow.org/guide/summaries_and_tensorboard [2019. 05. 14.]
[63] WP29 (2017): i. m., p. 28.
[64] Datatilsynet: i. m., pp. 21-22.
[65] GDPR 22. cikk (3) bekezdés
[66] Péterfalvi Attila et. al.: i. m., p. 201.
[67] WP29 (2017): i. m., p. 29. és Péterfalvi Attila et. al.: i. m., p. 201.
[68] Michael Veale et. al.: i. m., p. 403.
[69] Maja Brkan: Do algorithms rule the world? Algorithmic decision-making in the framework of the GDPR and beyond. International Journal of Law and Information Technology, 11. January 2019. DOI; 10.1093/ijlit/eay017 p. 13.
Lábjegyzetek:
[1] A szerző főosztályvezető-helyettes NAIH.
Visszaugrás
